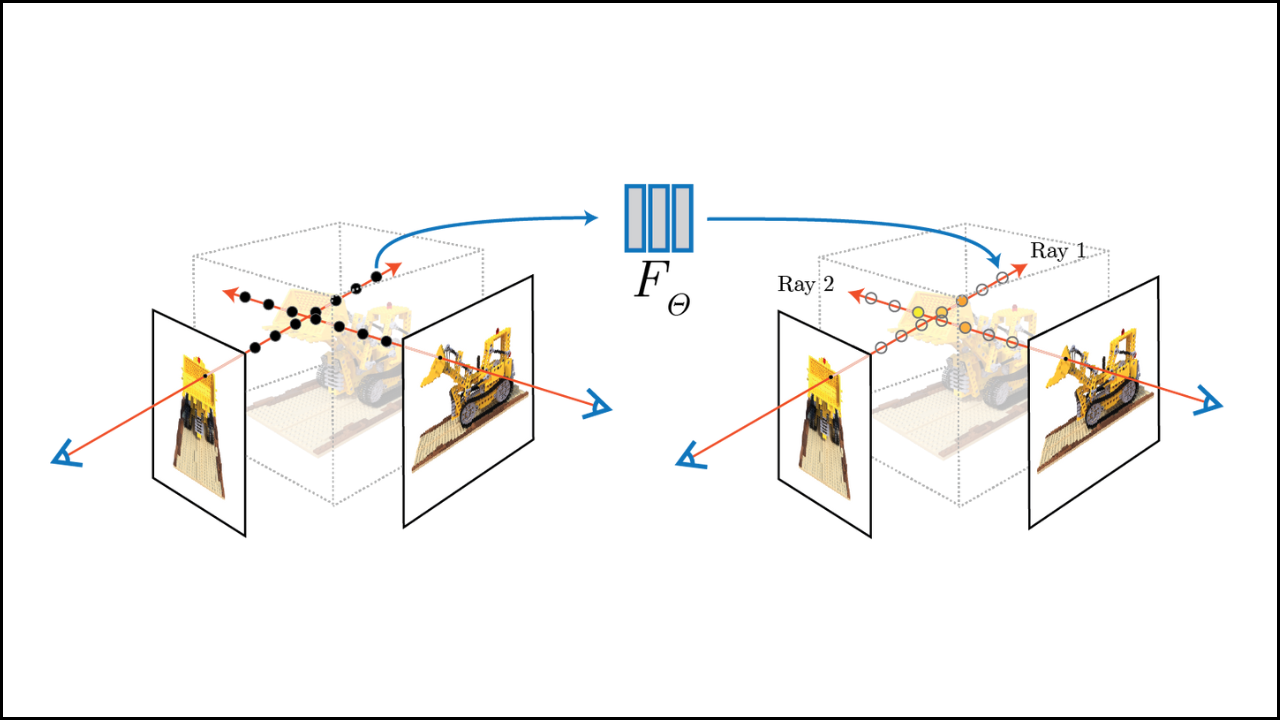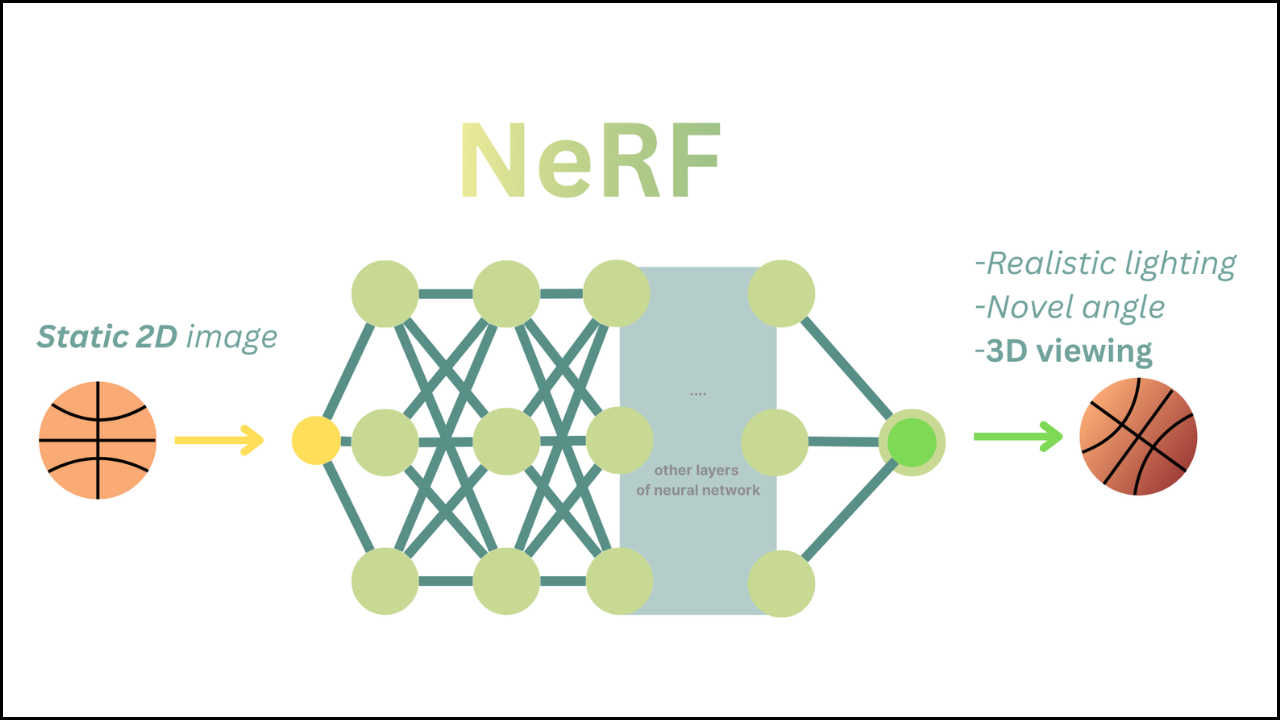
A clear comparison of PyTorch Lightning and standard PyTorch helps developers understand how each framework influences NeRF training speed, flexibility, and scalability. A structured view of training behavior, sampling customization, and rendering control allows NeRF practitioners to choose the workflow that fits their goals. A focused explanation highlights the strengths and limitations of both options in realistic NeRF pipelines.
Table of Contents
How Standard PyTorch Supports Full NeRF Customization
Standard PyTorch provides complete control over every training step, which is valuable for NeRF systems that require detailed sampling logic and custom rendering functions.
- Explicit training loops allow direct editing of raymarching, dynamic sampling, and hierarchical rendering logic.
- High transparency supports detailed debugging when tuning density fields or adjusting rendering weights.
- Direct control over device placement helps when handling large batches of rays or dense positional encodings.
- Flexible structure allows experimental NeRF variants without restrictions.
| NeRF Requirement | PyTorch Strength |
|---|---|
| Customized raymarching | Full control over per-step operations |
| Dynamic sampling logic | Direct modification inside training loop |
| Complex rendering equations | No forced structure or abstraction |
| Detailed debugging | Complete visibility into every component |
How PyTorch Lightning Streamlines NeRF Development
PyTorch Lightning simplifies the training process by removing repetitive code and managing common tasks automatically. NeRF models benefit from this structure when projects become large or require consistent organization.
- Clean separation of logic organizes model code, training steps, and evaluation behavior.
- Automatic training loop management eliminates boilerplate for optimizer steps and gradient updates.
- Stable multi-GPU execution becomes easy through Lightning Trainer configurations.
- Built-in checkpointing supports long NeRF training cycles without manual saving.
| Training Need | Lightning Benefit |
|---|---|
| Multi-GPU scaling | Built-in distributed capabilities |
| Long training stability | Automatic checkpoint handling |
| Reduced boilerplate | Managed device placement and loops |
| Team collaboration | Standardized module organization |
How Control and Abstraction Affect NeRF Workflows
NeRF training often requires fine-tuned control over rays, samples, and rendering steps. The difference in abstraction between these frameworks impacts how easily developers can adjust core behavior.
- Standard PyTorch supports unrestricted editing of sampling order, occupancy logic, and rendering math.
- Lightning abstracts many parts of the training loop, reducing hands-on control but increasing consistency.
- Callback mechanisms in Lightning allow partial customization without rewriting core logic.
- Research-heavy pipelines often lean toward standard PyTorch due to rapid experimentation needs.
| Aspect | Standard PyTorch Advantage | Lightning Adjustment |
|---|---|---|
| Ray sampling control | Fully customizable | Must follow callback or step layout |
| Rendering pipeline changes | Direct modification | Influenced by abstraction layer |
| Debug granularity | Full visibility | Requires hooks for deeper insight |
| Code flexibility | Maximum | Moderate |
How Performance and Efficiency Differ
NeRF workloads demand high performance because ray marching and volume integration are computationally heavy. Both frameworks influence efficiency differently.
- Standard PyTorch offers slightly faster execution for custom rendering because no abstraction layer exists.
- Lightning adds minimal overhead but contributes productivity advantages through automation.
- Mixed precision tools in Lightning simplify half-precision training for large scenes.
- Manual tuning in PyTorch allows specialized optimization for experimental NeRF variants.
| Performance Task | Standard PyTorch Benefit | Lightning Benefit |
|---|---|---|
| Kernel-level execution | No abstraction overhead | Slight overhead but efficient |
| Precision management | Manual and flexible | Automated AMP support |
| Training loop efficiency | Fully custom | Streamlined and predictable |
| Experiment tracking | User-managed | Integrated logging utilities |
How Distributed Training Differs
NeRF models scale well with multiple GPUs because of their heavy sampling workloads. The two frameworks manage scaling differently.
- Lightning simplifies distributed training through Trainer configurations without writing communication code.
- Standard PyTorch supports customized distribution strategies, useful for advanced NeRF research requiring custom sampling splits.
- Lightning handles synchronization internally, reducing developer responsibility.
- PyTorch allows fine control when adjusting per-GPU batch behavior.
| Scaling Requirement | Standard PyTorch Approach | Lightning Approach |
|---|---|---|
| Multi-GPU setup | Manually configured | Simple Trainer flags |
| Gradient synchronization | Customizable | Automatically handled |
| Distributed sampling logic | Fully flexible | Must fit Lightning design |
| Performance tuning | Custom strategies | Auto-managed defaults |
Moving Forward
A clear distinction between PyTorch Lightning and standard PyTorch reveals how differently they influence NeRF training workflows. Standard PyTorch provides unmatched flexibility for custom sampling and rendering research, while Lightning offers a structured, scalable environment suitable for large teams and production-level NeRF projects. A thoughtful selection between the two ensures that NeRF developers achieve both training efficiency and workflow clarity.