Neural Radiance Fields (NeRF) have transformed 3D scene reconstruction but remain data-hungry and slow to train. Research innovation. FrugalNeRF, introduced at CVPR 2025, addresses the core limitation of NeRF (NSF) by enabling fast convergence using very few input images. Practical relevance. This approach opens new possibilities for real-time and resource-efficient 3D reconstruction.
Table of Contents
Overview
| Key Aspect | Description |
|---|---|
| Research focus | Few-shot NeRF reconstruction |
| Main contribution | Faster convergence without learned priors |
| Input requirement | Extremely limited views (few images) |
| Core technique | Cross-scale geometric adaptation |
| Representation type | Multi-scale weight-sharing voxels |
| Application scope | AR/VR, robotics, rapid 3D capture |
Why Few-Shot NeRF Is Difficult
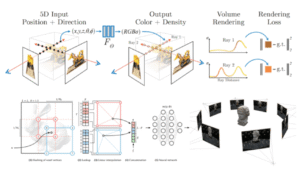
Traditional NeRF models require dozens or hundreds of images to learn accurate geometry and appearance. Training inefficiency. Optimization is slow because the neural network must learn the entire scene from scratch. Overfitting risk. With very few images, models tend to memorize views rather than generalize. Resource cost. Long training times make NeRF impractical for time-critical applications.
What Makes FrugalNeRF Different
FrugalNeRF focuses on using minimal data more effectively rather than adding external supervision. Prior-free learning. Unlike earlier methods, it does not rely on pre-trained models or learned priors. Efficient structure. The framework introduces architectural and training strategies that guide the model toward correct geometry quickly.
Multi-Scale Weight-Sharing Voxel Representation
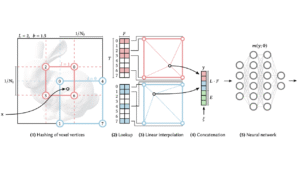
FrugalNeRF represents scenes using voxel grids at multiple resolutions. Information sharing. All voxel grids share parameters, allowing knowledge learned at one scale to benefit others. Coarse-to-fine learning. Low-resolution voxels capture global structure, while higher-resolution voxels refine details. Stability improvement. Weight sharing reduces overfitting and improves training stability in few-shot settings.
Representation Comparison
| Feature | Traditional NeRF | FrugalNeRF |
|---|---|---|
| Scene encoding | Single neural network | Multi-scale voxel grids |
| Parameter sharing | No | Yes |
| Few-shot stability | Low | High |
| Convergence speed | Slow | Fast |
| Overfitting control | Limited | Strong |
Cross-Scale Geometric Adaptation
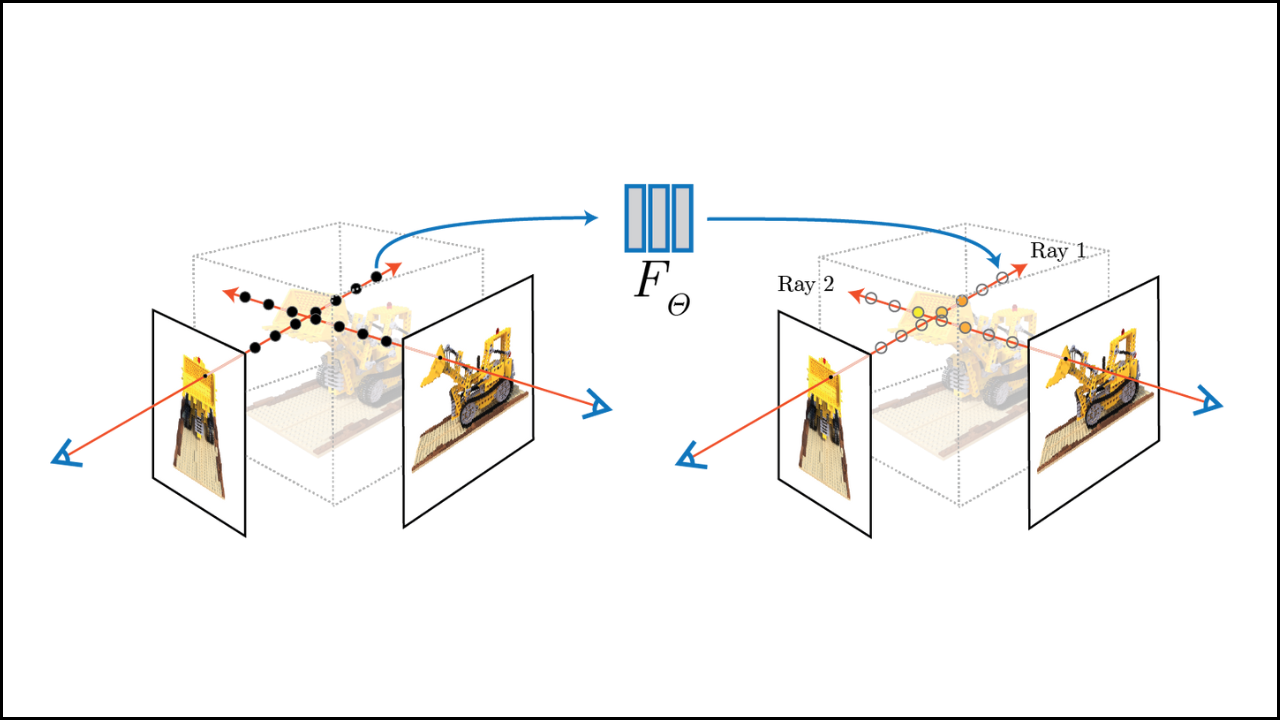
FrugalNeRF introduces a mechanism that compares predictions across voxel scales. Depth estimation. The model identifies the most reliable geometric scale and uses it as pseudo ground truth. Error minimization. Reprojection error guides optimization toward correct geometry. Training efficiency. This process accelerates convergence without external depth data or supervision.
Experimental Performance and Results
FrugalNeRF demonstrates strong reconstruction quality with only a handful of input views. Visual clarity. Reconstructed scenes show sharper geometry and fewer artifacts. Training speed. Models converge significantly faster compared to earlier few-shot NeRF approaches. Generalization. Performance remains stable across indoor and outdoor scenes.
Comparison With Previous Few-Shot NeRF Methods
Some approaches use frequency or appearance constraints but still require long training. Prior-dependent models. Other methods depend on large pre-trained datasets, introducing bias. FrugalNeRF advantage. It avoids both limitations by using internal geometric consistency across scales.
Method Comparison
| Aspect | Prior Methods | FrugalNeRF |
|---|---|---|
| Learned priors | Often required | Not required |
| Training complexity | High | Moderate |
| Data efficiency | Limited | Very high |
| Generalization | Dataset-dependent | Scene-agnostic |
| Practical usability | Restricted | Broad |
Applications Enabled by FrugalNeRF
Rapid scene reconstruction supports immersive content creation. Robotics. Robots can build 3D maps with minimal visual input. Cultural preservation. Heritage sites can be reconstructed with limited imagery. Interactive graphics. Game engines and simulations benefit from fast scene modeling. Mobile capture. Efficient training enables on-device or near-device processing.
Limitations and Research Considerations
Performance may degrade with severely constrained viewpoints. Memory usage. Multi-scale voxel grids increase memory requirements. Scene complexity. Highly reflective or dynamic scenes remain challenging. Ongoing research. Further optimization can improve scalability and robustness.
In Summary
FrugalNeRF represents a major advancement in few-shot NeRF reconstruction. Efficiency breakthrough. By achieving fast convergence without learned priors, it addresses one of the biggest barriers to real-world NeRF adoption. Broader impact. The method expands the usability of 3D reconstruction across industries and research domains, marking FrugalNeRF as a standout contribution at CVPR 2025.
FAQs
Q: What problem does FrugalNeRF solve?
A: It enables fast and accurate NeRF reconstruction using very few images.
Q: Does FrugalNeRF rely on pre-trained models?
A: No, it works without learned priors or external supervision.
Q: Why is FrugalNeRF important for real-world use?
A: Its fast convergence makes NeRF practical for time- and resource-limited applications.