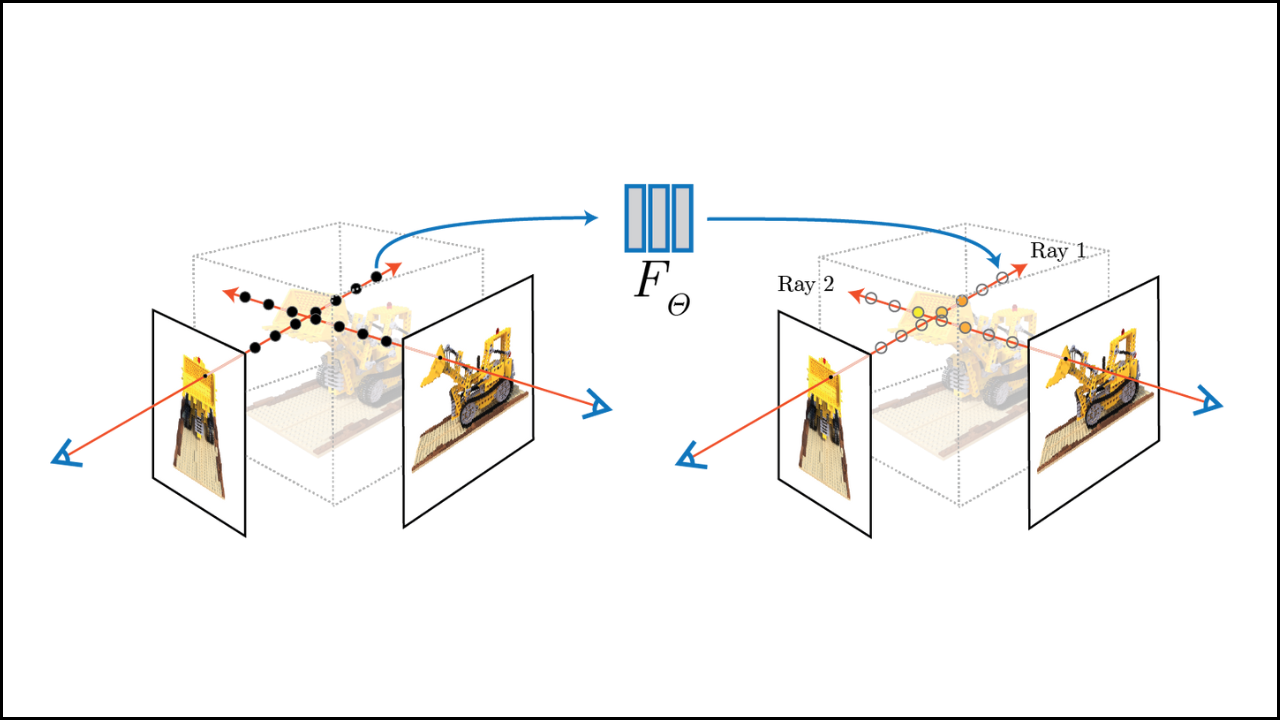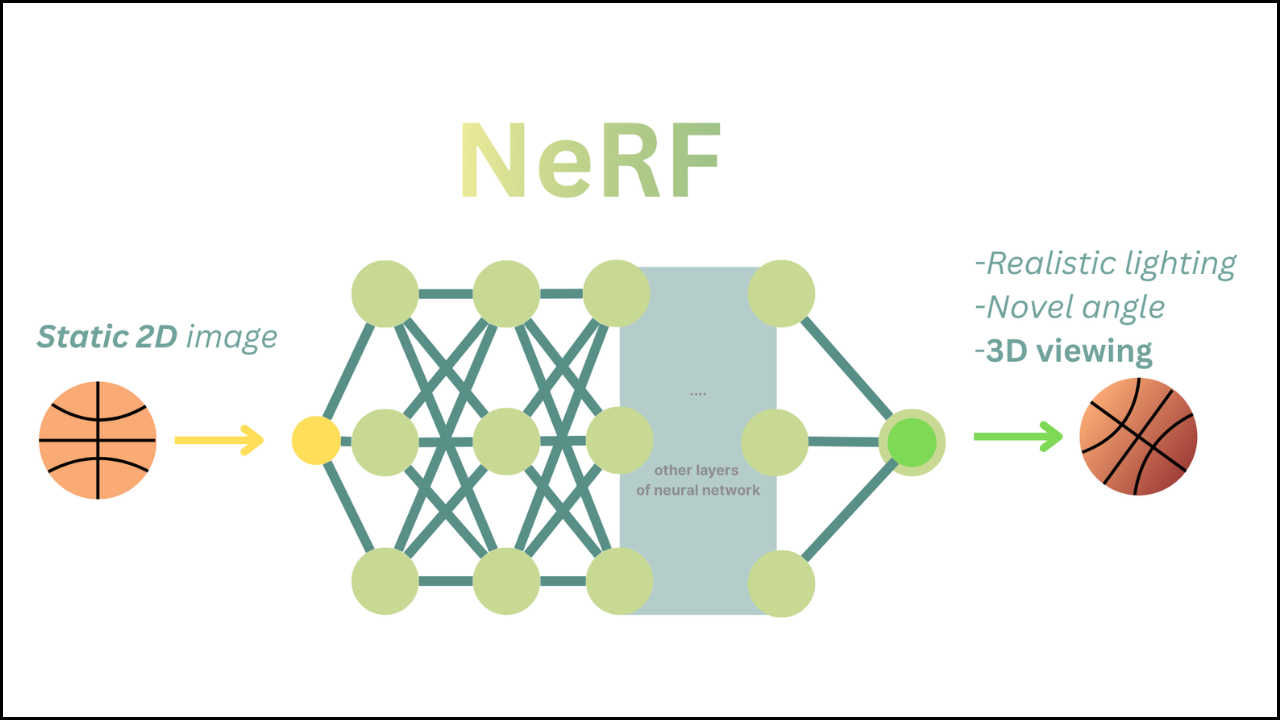
PyTorch creates a flexible and efficient foundation for building modern NeRF systems that depend on dynamic architectures, heavy GPU computation, and continuous experimentation. A combination of dynamic execution, GPU-accelerated tensor operations, automatic differentiation, and smooth integration with tools such as NerfAcc allows NeRF pipelines to achieve high-quality rendering and faster training performance. A strong structure provided by PyTorch supports research-focused workflows and production models equally well.
Table of Contents
How PyTorch Enables Dynamic NeRF Architecture Design
A NeRF model requires flexible components such as encoders, MLP blocks, and sampling logic. PyTorch supports this through its dynamic execution model.
- Dynamic graphs handle conditional sampling and view-dependent shading.
- Modular layers allow quick changes in network structure.
- Custom extensions integrate CUDA kernels and acceleration libraries.
| NeRF Requirement | PyTorch Advantage |
|---|---|
| Flexible encodings | Modular layers and custom functions |
| Adaptive sampling logic | Runtime graph construction |
| Custom rendering operations | Direct CUDA extension support |
| Research experimentation | Fast prototyping without static constraints |
How PyTorch Accelerates NeRF Training Through GPU Optimization
A NeRF pipeline processes millions of samples and rays. PyTorch optimizes these operations through its GPU-driven tensor engine.
- Fused kernels minimize unnecessary launches.
- CUDA-optimized operations accelerate positional encodings and activations.
- Parallel batch execution handles thousands of rays efficiently.
- Broadcasting reduces repetitive computation.
| Operation | PyTorch GPU Capability |
|---|---|
| Ray direction normalization | Vectorized high-speed operations |
| Positional encoding | Fast CUDA-based elementwise kernels |
| MLP computation | cuBLAS-backed matrix multiplications |
| Volume rendering integration | Efficient GPU broadcasting and reduction |
How Autograd Simplifies NeRF Optimization
A NeRF system depends on gradients flowing through density prediction, color estimation, and hierarchical sampling. PyTorch handles these automatically.
- Automatic differentiation eliminates manual derivative coding.
- Graph retention keeps gradient paths across many samples.
- Custom backward functions allow fine control for experimental regularizers.
| NeRF Computation | Autograd Support |
|---|---|
| Density gradients | Automatically computed through ray steps |
| Color loss | Fully backpropagated across rendering pipeline |
| View-dependent features | Gradient paths preserved in direction encoders |
| Importance weight updates | Differentiable probability-based updates |
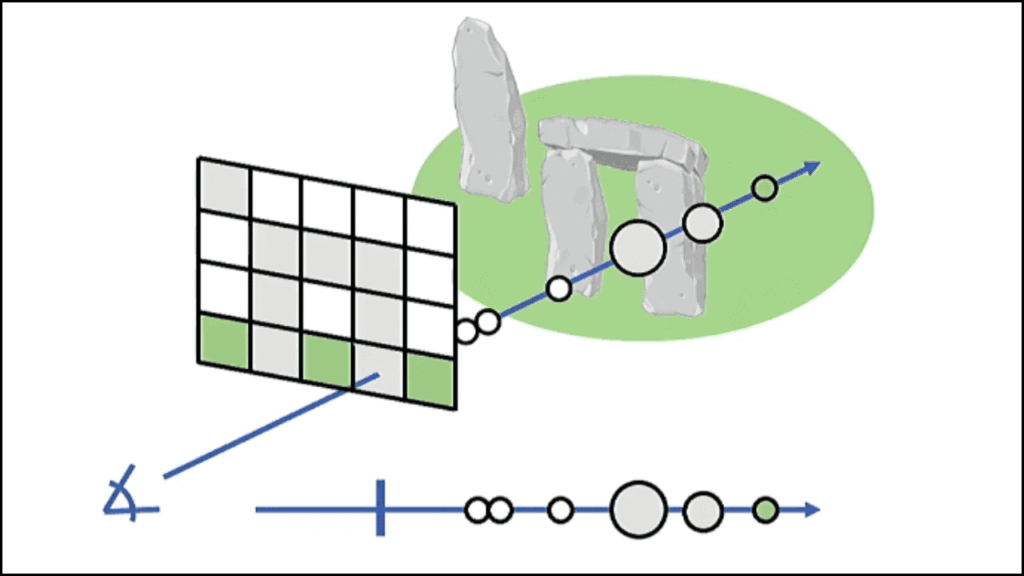
How PyTorch Enhances NeRF Sampling and Raymarching Efficiency
A NeRF rendering pipeline depends on efficient sampling to avoid wasted computation. PyTorch improves this through optimized tensor operations.
- Vectorized raymarching processes rays in large batches.
- Differentiable sampling integrates coarse-to-fine strategies smoothly.
- NerfAcc compatibility accelerates occupancy pruning and ray skipping.
- Memory-efficient tensors manage large sample sets effectively.
| Sampling Process | PyTorch Benefit |
|---|---|
| Ray–voxel intersection | Fast parallel comparisons |
| Coarse sample generation | Simple tensor-based distributions |
| Fine-sample refinement | GPU-accelerated sorting and selection |
| Sample weight updates | Differentiable mathematical operations |
How PyTorch Supports Large-Scale NeRF Training
A complete NeRF system needs large datasets, long training schedules, and multi-GPU scaling. PyTorch provides tools for all of these.
- Distributed Data Parallel supports efficient multi-GPU execution.
- Automatic Mixed Precision reduces memory use and increases speed.
- Checkpoint features maintain long-running training stability.
- JIT compilation optimizes performance during experiments.
| Scaling Need | PyTorch Solution |
|---|---|
| Multi-GPU workloads | Distributed Data Parallel |
| Lower memory usage | Mixed precision training |
| Stable long-duration runs | Robust checkpointing |
| Faster experiments | TorchScript and JIT tools |
How PyTorch Integrates With NeRF Acceleration Frameworks
A modern NeRF pipeline requires fast sampling, pruning, and grid-based optimization. PyTorch integrates smoothly with external accelerators.
- NerfAcc compatibility enables fast occupancy grids and sample pruning.
- Custom CUDA ops extend the system for research features.
- Community tools evolve with new NeRF innovations.
- Unified data pipelines keep image and ray handling consistent.
| Add-on Component | Integration Benefit |
|---|---|
| NerfAcc | Direct tensor compatibility for fast sampling |
| CUDA kernels | Clean and simple extension APIs |
| Research libraries | Frequently updated community ecosystem |
| Data loaders | Unified handling of rays, masks, and images |
Looking Ahead
A well-designed blend of dynamic execution, GPU-optimized computation, and automatic differentiation allows PyTorch to power modern NeRF systems with strong efficiency and flexibility. A smooth integration with acceleration tools strengthens every stage of the pipeline, from sampling to rendering to large-scale optimization. A stable foundation created by PyTorch ensures that NeRF workflows remain scalable, innovative, and ready for future improvements.