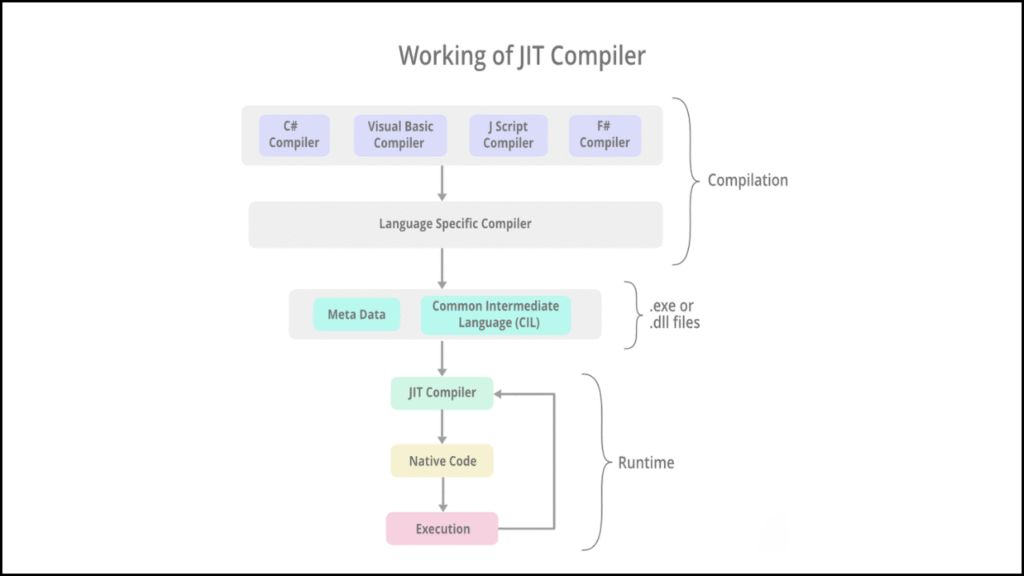
TorchScript support enables NeRF models to run faster by turning Python-based components into optimized intermediate representations that execute with reduced overhead. Scripted and traced modules eliminate Python’s dynamic dispatch, reduce kernel launch latency, and enable deeper fusion of dense mathematical operations used throughout raymarching and MLP evaluation. NeRF pipelines gain speed, stability, and predictable execution when TorchScript is applied to the most expensive computational paths.
Table of Contents
Understanding Why TorchScript Helps NeRF
Python overhead removal allows NeRF sampling loops and MLP passes to run without interpreter delays.
Kernel fusion becomes possible when JIT identifies patterns in matrix operations and elementwise computations.
Ahead-of-time optimization reduces repeated graph construction during training.
Static graph execution ensures more predictable performance for complex sampling logic.
CUDA efficiency gains arise from fewer dispatches and more tightly packed operations.
TorchScript Feature
NeRF Advantage
Static graph execution
Faster and more predictable MLP and sampling performance.
Python-free kernels
Reduced overhead in ray loop iterations.
Graph optimization
Fusion of common NeRF math operations.
Trace caching
Reuse of optimized kernels during training.
Consistent execution
Stable runtime behavior across iterations.
TorchScript Options for NeRF
Tracing captures operations during a single forward pass and builds an execution graph.
Scripting analyzes Python code and compiles conditional logic inside sampling and raymarching blocks.
Hybrid approaches combine tracing for MLPs and scripting for sampling functions.
Selective compilation focuses on the areas that bring the highest performance gains.
JIT modules store optimized functions for repeated use across epochs.
Approach
NeRF Use Case
Tracing
Smoothly structured MLPs with fixed input shapes.
Scripting
Control-flow-heavy raymarching and sampling loops.
Hybrid
MLP traced; sampling scripted.
Selective compilation
Only bottlenecks compiled for speed.
JIT modules
Cached reusable components for large-scale training.
JIT Compilation and the NeRF MLP Stack
Fully connected layers benefit from fused matrix operations.
Activation functions run inside optimized kernels rather than Python loops.
View-dependent components execute faster with repetitive fused instructions.
Batch evaluation improves when JIT removes overhead from repeated forward calls.
Mixed precision support integrates well with JIT-generated kernels.
MLP Component
Speedup from JIT
Layer multiplications
Reduced kernel calls through fusion.
Activations
Faster execution inside optimized graphs.
Positional encoding
Fused sine/cosine transformations.
View-dependent branch
Lower latency from merged operators.
Batch inference
Higher throughput per ray batch.
JIT-Accelerated Raymarching and Sampling
Sampling loops often contain Python-based branching that slows execution.
Scripted sampling allows complex control flow to run directly on the GPU where possible.
Step-size logic becomes faster when TorchScript removes interpreter checks.
Fine sampling benefits from repeated low-level operations being fused.
Distance and density lookups experience reduced latency with optimized kernels.
Sampling Stage
TorchScript Effect
Coarse sampling
Streamlined loops with fewer Python calls.
Fine sampling
Less overhead in per-ray refinement.
Step computation
More efficient handling of dynamic increments.
Density queries
Faster repeated calls to the MLP.
Transmittance updates
Optimized accumulation using fused code paths.
TorchScript and CUDA Kernel Interaction
Reduced launch overhead leads to fewer dispatch delays during dense sampling.
Kernel fusion combines elementwise ops that previously launched separately.
Better warp usage becomes possible when compiled code removes unnecessary branches.
Memory access patterns improve with rearranged ops inside the compiled graph.
Consistent shapes allow kernels to run with predictable speed.
CUDA Behavior
Impact on NeRF
Lower launch count
Faster training and inference cycles.
Fused kernels
Higher throughput per ray batch.
Optimized memory reads
Faster sampling and interpolation.
Reduced divergence
More uniform behavior across rays.
Stable scheduling
Less jitter in runtime performance.
Practical Workflow for Adding TorchScript to NeRF
Trace MLP networks first, since they usually produce immediate speedups.
Script sampling functions that contain conditional logic are not suited for tracing.
Validate output consistency to ensure no mismatches with Python models.
Cache compiled graphs to reuse across epochs and experiments.
Profile before and after to measure changes in operator counts and kernel durations.
Pipeline Step
Action
MLP preparation
Trace model with representative inputs.
Sampling logic
Script raymarch loops containing conditionals.
Validation
Compare outputs with original Python functions.
Caching
Store compiled graph for stable reuse.
Profiling
Check speedup and kernel fusion impact.
Common Issues and Fixes
Unsupported Python constructs require rewriting loops or replacing dynamic data types.
Shape mismatches break traced graphs when input sizes change unexpectedly.
Divergent control flow may need scripting instead of tracing.
Silent fallbacks occur when unsupported ops revert to Python.
Debugging difficulty increases with compiled graphs unless carefully logged.
Where TorchScript Gives the Best Speed Gains
High-density scenes with many fine samples per ray.
Large MLPs with frequent repeated evaluations.
GPU-limited pipelines where Python overhead becomes noticeable.
Real-time NeRF applications that need deterministic latency.
Interactive reconstruction systems rely on rapid feedback loops.
The Way Forward
TorchScript and JIT compilation strengthen NeRF performance by removing Python overhead, fusing critical operations, and generating optimized graph representations for raymarching and neural inference. JIT-enhanced code reduces kernel dispatch costs, accelerates MLP layers, and stabilizes ray sampling loops, producing significant improvements in both training speed and rendering efficiency.
She is a creative and dedicated content writer who loves turning ideas into clear and engaging stories. She writes blog posts and articles that connect with readers. She ensures every piece of content is well-structured and easy to understand. Her writing helps our brand share useful information and build strong relationships with our audience.